manually roll Splunk buckets from hot to warm
As you might know indexes are where your data in splunk is stored. An index contains of time-based buckets (directories). Over time a bucket – the indexed data – is rolling from hot (when data is still written to the bucket) to warm (data is read-only) to cold. When you want to backup Splunk you need the data in a consistent state – in a warm bucket.
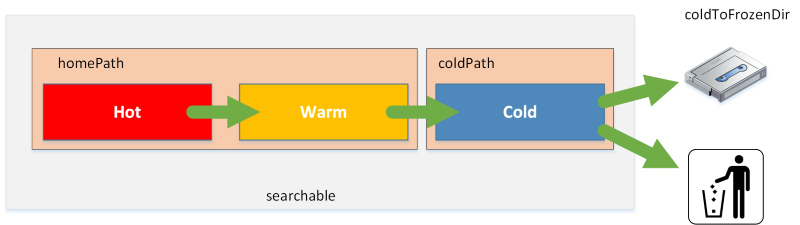
There are different situations when a bucket is rolled from hot to warm:
- restart of the splunk service
- parameter maxDataSize in indexes.conf is hit (750MB default, 10GB with auto_high_volume)
here’s an overview of indexes.conf parameters:
As you see there is no time but only a size value when Splunk rolls a bucket from hot to warm. There are situations where you manually want to roll a bucket from hot to warm. Here is a hot bucket in an index named “bwindex” with the ID 37.
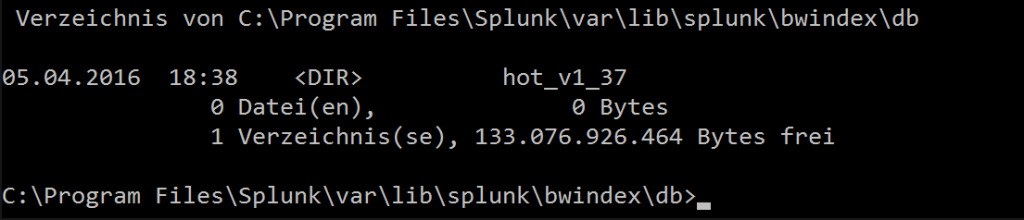
You can force Splunk to roll the bucket with using this command: splunk _internal call /data/indexes/INDEXNAME/roll-hot-buckets -auth admin:password Where INDEXNAME the name of the index to roll.

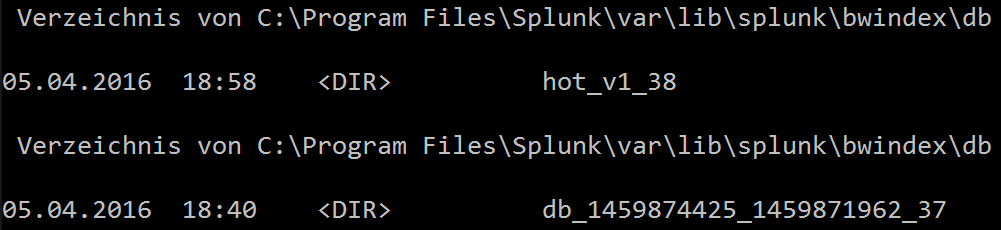
You can also trigger the rolling on a remote indexer using curl: curl –k https://localhost:8089/services/data/indexes/bwindex/roll-hot-buckets -x POST -u admin:password After that we check again on the hot buckets and see that there is a new hot bucket with ID 38. The old bucket has been renamed to db_timestamp_timestamp_ID.
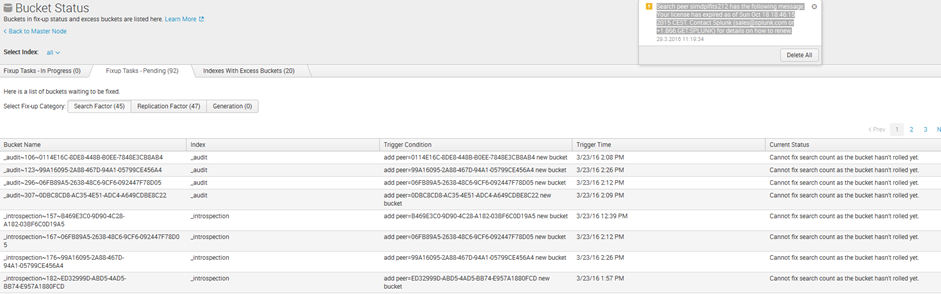
There might be situations in the real world where you want to roll the hot buckets manually. There was an index replication cluster where the search factor and replication factor wasn’t met. The error message was “Cannot fix search count as the bucket hasn’t rolled yet”. As this could take up to 90 days to complete (if the data volume is small enough) we want to force the indexer to roll the bucket.
There is a screenshot:
Splunk v6.4
There is a feature easy to overlook in Splunk6.4 which is named “Force roll specific hot buckets“. You can find the documentation here. There is a new REST endpoint /services/cluster/master/control/control/roll-hot-buckets – which makes your life easier. In older versions you need to determine the concrete indexer by matching the GUID from the bucket information (e.g.: _audit~2~1A3889D7-954B-4CE6-B071-01B438DE9865) and send the REST request to the cluster peer directly.
old method – pre v6.4(for every indexer and bucket):
- determine the indexer with rest query
| rest /services/cluster/master/peers splunk_server=local | table id label status last_heartbeat - roll the bucket:
curl –k https://clusterpeer:8089/services/data/indexes/INDEXNAME/roll-hot-buckets -x POST -u admin:password
Now you can force the cluster master to advice the cluster peer to roll the bucket.
new method (for every bucket):
curl -k -u username:password https://localhost:8089/services/cluster/master/control/control/roll-hot-buckets -X POST -d "bucket_id=_audit~2~1A3889D7-954B-4CE6-B071-01B438DE9865"
Hope this helps..